#1 GPU 이용 사이트
vast.ai 가 굉장히 gpu도 다양하고 싼 편이라고 함.

위와 같이 어떤 GPU에 얼마인지 나온다.
중요한 건 GPU 메모리 뿐만 아니라, 인터넷 속도 또한 중요하다.
일단 이번 프로젝트에서는 큰 모델 학습용이 아니라, 작은 모델 추론용이기 때문에 12GB 짜리를 찾아보려고 한다.

일단 목록 중에 가장 저렴하고 빠른 편인 GPU.
이제 미리 만들어 둔 자신의 환경에 맞는 템플릿에
서버를 빌리면서 인스턴스를 할당해주면 된다.
#2 Template GPU 환경 구성시 확인할 것
1. 다양한 기본 환경
여러가지 환경을 기본으로 세팅할 수 있는데,
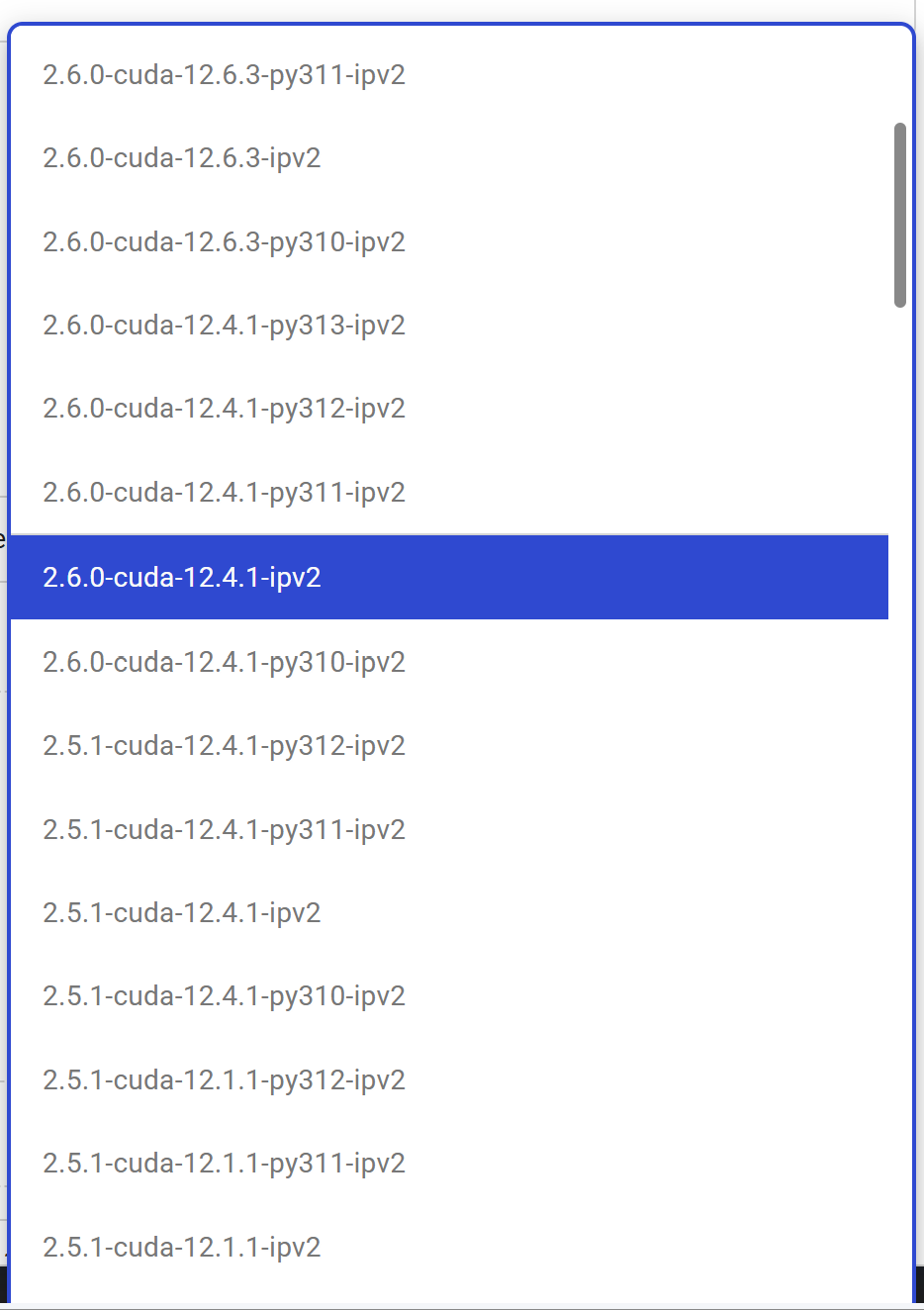
다음과 같이 다양하게 고를 수 있다.
뒤에는 버전 안내이다.

2. 포트 설정
현재 fast api 서버에서 열어둘 8080 포트만 열어둔다.
TCP는 신뢰성을 보장하는 프로토콜로, 데이터 손실 시 재전송 등의 로직이 있다.
웹 서버, Jupyter Notebook, REST API, DB 등의 서비스는 모두 TCP이다.
UDP를 고르는 경우는 비연결성에 실시간성을 더 중요하게 생각하는 경우이다. 영상이나 음성 스트리밍, 실시간 게임 같은 어플리케이션에 주로 사용된다.

3. 그 외 설정들 가이드라인

4. ssh 연결
1) ssh 키를 만든다
2)
cd ~/.ssh/이동해서 ssh 키 확인. 공개키를 넘긴다.
이렇게 연결한 후, vim known_hosts 로 파일을 열면 여태까지 ssh로 연결한 호스트들을 확인할 수 있다.
연결하는 명령어는 아래와 같다.
ssh -p 40711 root@64.46.12.35 -L 8080:localhost:80808080:localhost:8080 은 포트포워딩 명령어이다.

설정하고 보면 다음과 같이 서버 상태를 볼 수 있는데
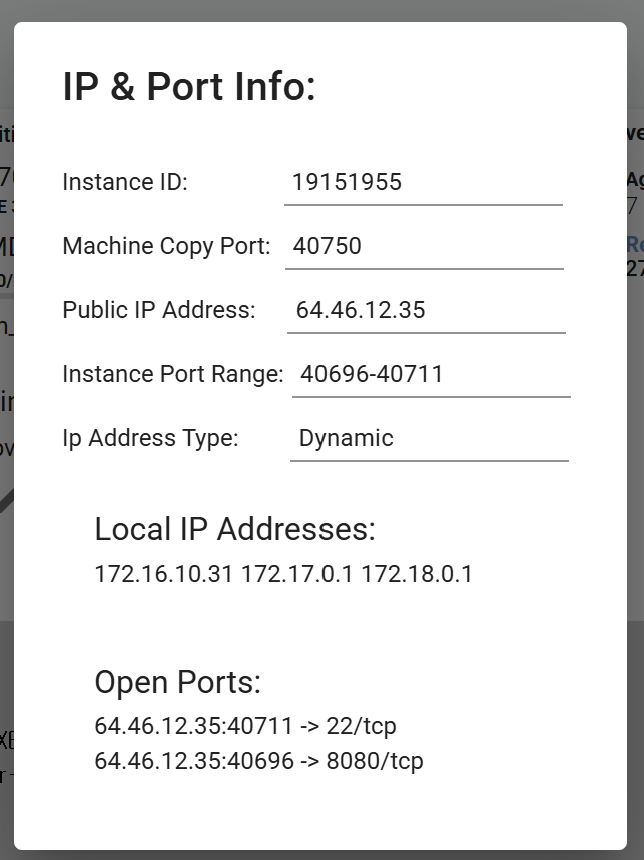
어디 포트가 열려있는지 알 수 있다. 외부 ip 주소 + 방화벽을 연 포트이기 때문에 이걸로 api 접근이 가능하다.
주의사항!!!

인스턴스를 멈춰도 코드 보관 비용이 하루에 얼마가 발생한다.
아예 파괴해야 돈이 안 나감.
* 주의 사항2
GPU서버를 빌려주면서 도커나 가상환경을 이미 사용하는지 기존 도커 환경을 실행하면 상당히 문제가 많이 발생했다.
따라서 서버 내에서는 도커 환경을 하지 않고,
CUDA 설정 등은 이미 처음에 해두었기 때문에 의존성을 다운로드 받아서 실행했다.
현재 프로젝트에서는 아래 명령어로 실행했다. 프로젝트 마다 상이.
python3.10 main.py --host 0.0.0.0 --port 8080
'프로젝트 기록 > 음성 AI를 사용한 쇼츠 생성 사이트' 카테고리의 다른 글
| 개발 리뷰 -7- SSH키 발급 및 공개키를 통한 GCP 공통 사용 (0) | 2025.03.18 |
|---|---|
| 개발 리뷰 -4- CORS 정책은 왜 Postman 요청은 막지 않는가? (0) | 2025.03.13 |
| 개발 리뷰 -1- Zonos 음성 모델 (0) | 2025.03.03 |





